How to Validate Word Counts for SEO
by Christoph Schiessl on JavaScript
Recently, I wrote an article to extract a list of pages from a sitemap.xml file and another one showing how to fetch each of these pages and extract their titles and meta descriptions. The reason for doing this was to validate the length — the number of characters — of the titles and descriptions for SEO purposes. You see, titles and descriptions are supposed to be below a certain number of characters for optimal SEO results.
Today, I want to go one step further and validate the same pages' word counts because there is another piece of advice floating around on the Internet: the number of words on pages should be above a certain threshold. There are, of course, exceptions — highly successful pages with low word count — but, statistically speaking, pages with higher word counts tend to perform better on search engines. There is no widely accepted consensus on the minimum number of words. Still, the impact on pages with less than 1000 words seems particularly noticeable, so I decided to aim for that. This means pages with 1000 words or more are good, and pages with less than that should be re-considered for improvement.
To implement this validation, we first need a JavaScript function that takes an HTML document as input and returns an integer representing the number of words in the document.
Getting the <body> element
So, given an object that implements the Document interface, we must first get its <body> element. I'm working with window.document for now because it's automatically available, but any Document object would work, including those you create yourself (e.g., with DOMParser). That said, I'm using the querySelector() method to get the document's <body> element — if there is no such element, then this method returns null, which we would have to handle, of course, in a real-world application.
const doc = window.document; // or any object implementing the Document interface
const bodyElement = doc.querySelector("body");
Getting the <body>'s text
Once we have a Node object representing the <body> element, we must extract its text, but using its textContent property would not be completely honest in this context. Instead, it's better to use its innerText property, whose behavior is slightly different because it only returns visible text. So, invisible text — that's, for instance, hidden due to some CSS rule — is not included in the returned String. Since we want to count the words on the page, or in other words, measure the length of the content visitors experience, it's better to use the property closer to the user's experience when they view the page.
const bodyText = bodyElement.innerText;
Cleaning up the text
Next, we must clean up the text to strip out all characters that do not constitute a proper word. For that, I want to use the replaceAll() method of String objects with a regular expression. Essentially, I want to count sequences of one or more "word characters", for which we can use JavaScript's built-in character class \w. The official documentation explains this as follows:
Matches any alphanumeric character from the basic Latin alphabet, including the underscore. Equivalent to
[A-Za-z0-9_]. For example,/\w/matches"a"in"apple","5"in"$5.28", and"3"in"3D".
So, sequences of word characters are what we need to count in the end, but for filtering, we need precisely the opposite. Luckily, JavaScript also has an inverse character class called \W, which matches everything except word characters. The official documentation states:
Matches any character that is not a word character from the basic Latin alphabet. Equivalent to
[^A-Za-z0-9_]. For example,/\W/or/[^A-Za-z0-9_]/matches"%"in"50%".
Note that \W also matches white space characters like spaces and line breaks. So, for the replacement, I'm replacing all sequences of one or more non-word characters with a single space. This is a good approach that will be handy, as you'll see in a minute.
const bodyTextClean = bodyText.replaceAll(/\W+/g, " ");
One last point: the regular expression for replaceAll() must use the global flag because otherwise, replaceAll() raises an exception, which would abort the execution of our script.
Splitting the text and counting the number of words
We can use a simple split() to convert the cleaned text to an Array containing all space-separated words. Given the previous step, we can conclude that these words must be sequences of word characters as defined above.
const listOfWords = bodyTextClean.split(" ");
const wordCount = listOfWords.length;
Finally, we take the Array's length property, which is, of course, the number of words we have been looking for.
Putting everything together
So, for convenience, we can combine all the steps we have discussed so far into a function for later re-use. The only difference here is that I added an early exit to return a word count of 0 for documents that don't have a <body> element.
function countNumberOfWords(doc) {
const bodyElement = doc.querySelector("body");
if (bodyElement === null) return 0;
const bodyText = bodyElement.innerText;
const bodyTextClean = bodyText.replaceAll(/\W+/g, " ");
const listOfWords = bodyTextClean.split(" ");
return listOfWords.length;
}
With that said, we can now test our function in the console, using window.document as input, to determine the word count of some page.
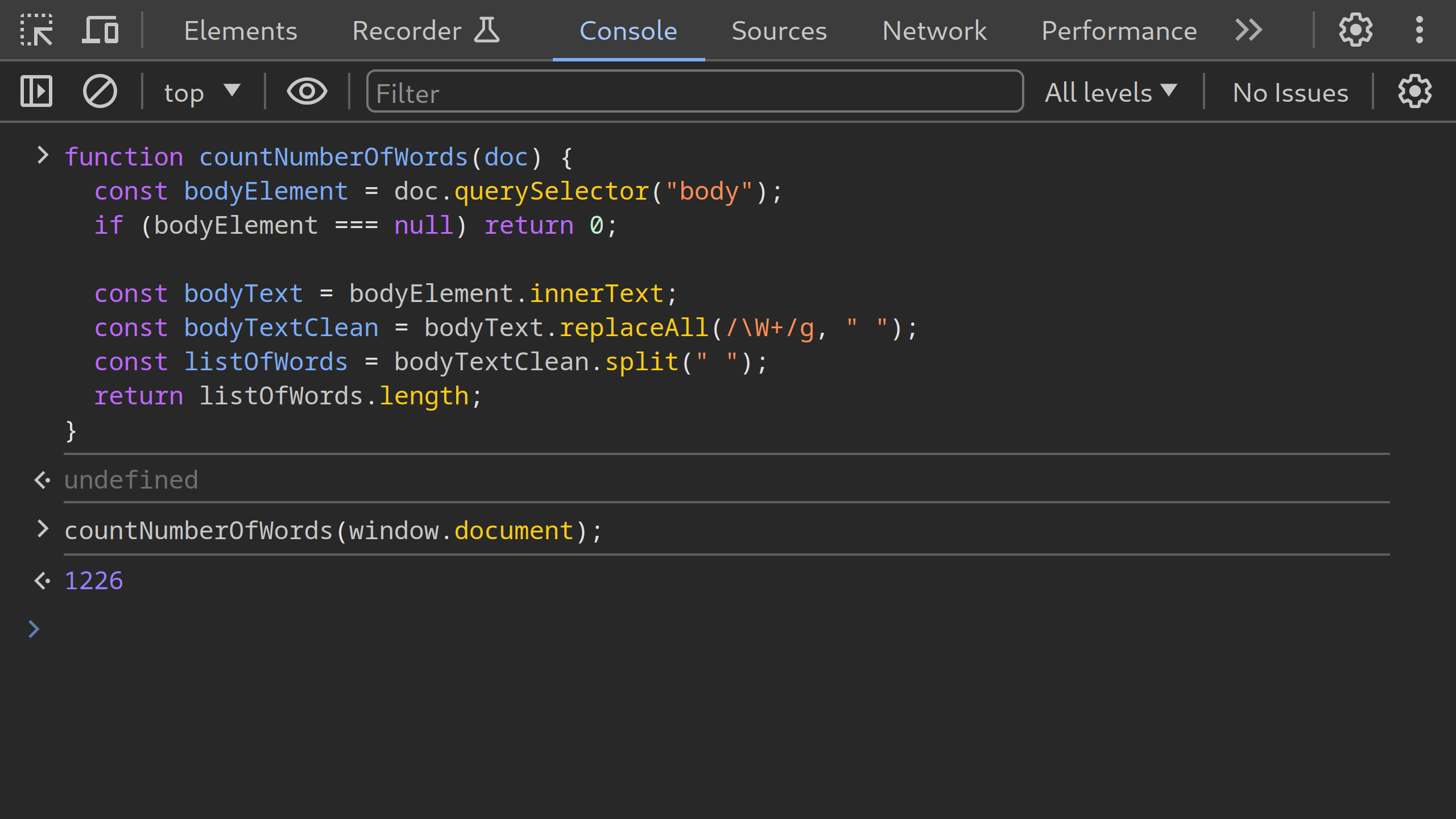
The current page, window.document, has a word count of 1226.
If you also read my previous articles, it should be straightforward to integrate word counting into the script to validate the titles and descriptions of all pages mentioned in your /sitemap.xml. Anyway, for the sake of completeness, I'm putting the complete code below:
async function extractPageURLsFromSitemapXML() {
let rawXMLString = await fetch("/sitemap.xml").then((response) => response.text());
let parsedDocument = (new DOMParser()).parseFromString(rawXMLString, "application/xml");
let locElements = parsedDocument.querySelectorAll("loc");
return locElements.values().map((e) => e.textContent.trim()).toArray();
}
function countNumberOfWords(doc) {
const bodyElement = doc.querySelector("body");
if (bodyElement === null) return 0;
const bodyText = bodyElement.innerText;
const bodyTextClean = bodyText.replaceAll(/\W+/g, " ");
const listOfWords = bodyTextClean.split(" ");
return listOfWords.length;
}
async function extractPageTitleAndDescription(pageURL) {
let title = null, description = null;
let response = await fetch(pageURL);
let rawHTMLString = await response.text();
let parsedDocument = (new DOMParser()).parseFromString(rawHTMLString, "text/html");
let titleElement = parsedDocument.querySelector("head > title");
if (titleElement !== null) { title = titleElement.textContent.trim(); }
let descriptionElement = parsedDocument.querySelector("head > meta[name=description][content]");
if (descriptionElement !== null) { description = descriptionElement.getAttribute("content").trim(); }
return { title, description, wordCount: countNumberOfWords(parsedDocument) };
}
const pagesWithErrors = {};
for (const pageURL of await extractPageURLsFromSitemapXML()) {
const { title, description, wordCount } = await extractPageTitleAndDescription(pageURL);
const errors = [];
if (title === null) { errors.push('title missing'); }
else if (title.length > 70) { errors.push(`title too long ${title.length}`); }
if (description === null) { errors.push('description missing'); }
else if (description.length > 160) { errors.push(`description too long ${description.length}`); }
if (wordCount < 1000) { errors.push(`word count too small ${wordCount}`); }
if (errors.length > 0) { pagesWithErrors[pageURL] = errors.join(", "); }
}
console.table(pagesWithErrors);
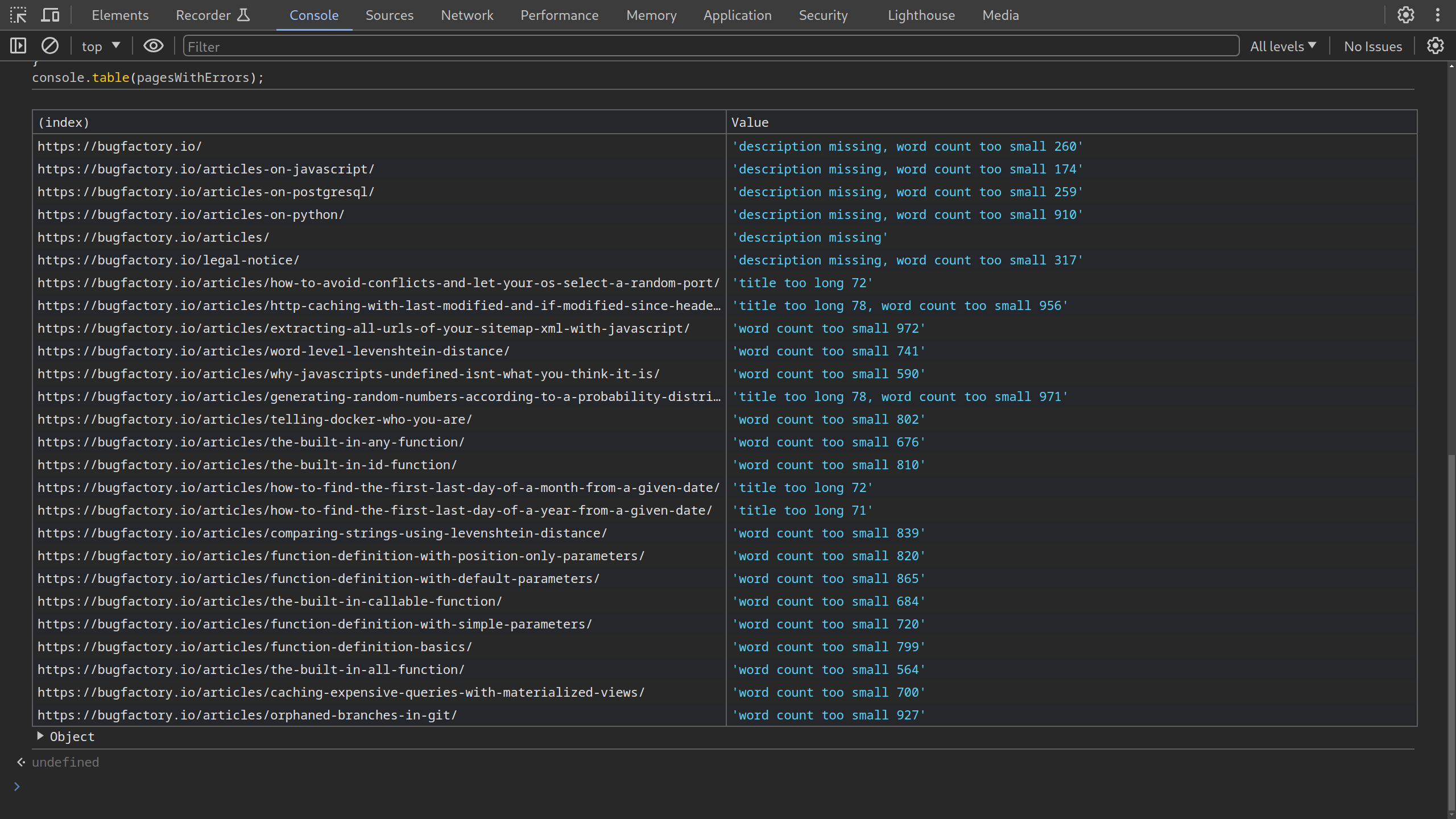
List of pages, extracted from the /sitemap.xml of bugfactory.io, that are violating at least one SEO rule.
Please don't hesitate to reach out if you have any questions. Thank you for reading, and see you soon!

